Creating 3D Line Drawings
June 30th, 2025
This is an experiment examining how to create a 3D line drawing of a scene. In this post, I will describe how this can be done by augmenting the process of generating 3D Gaussian Splats3D Gaussian Splatting for Real-Time Radiance Field Rendering, by Kerbl et al. and leveraging a process to transform photographs into Informative Line DrawingsLearning to Generate Line Drawings that Convey Geometry and Semantics, by Chan, Isola & Durand.
Examples
The majority of scenes shown above are generated using a contour style. You can switch the active scene using the menu in the top-right corner of the iframe. Each scene is trained for 21,000 iterations on an Nvidia RTX 4080S, using gaussian-splatting-cuda from MrNerf with default settings. Examples here were generated using scenes from the Tanks & Temples Benchmark. The scene is interactive, and rendered using Mark Kellogg's web-based renderer.
To explore these scenes in fullscreen, click here.
How it works
Creating Line Drawings from Images
 Figure 1. (a) A source image from the Caterpillar scene in Tanks & Temples. (b) A generated line drawing in the contour style. (c) A generated line drawing in the anime style.
Figure 1. (a) A source image from the Caterpillar scene in Tanks & Temples. (b) A generated line drawing in the contour style. (c) A generated line drawing in the anime style.Images are transformed into line drawings using the approach introduced by Chan et al. in Learning to Generate Line Drawings that Convey Geometry and Semantics. They describe a process for transforming photographs into line drawings that preserve the semantics and geometry captured in the photograph while rendering the image in an artistic style. They do this by training a generative adversarial network (GAN) that minimizes geometryThe geometry loss is computed using monocular depth estimation., semanticsThe semantics loss is computed using CLIP embeddings., and appearanceThe appearance loss is based on a collection of unpaired style references. losses. Their work is fantastic and I recommend reading their paper if you're interested in the details. Figure 1 depicts the input photograph and output line drawing in two styles, generated using Chan et al.'s code and model weights.
3D Gaussian Splatting
3D Gaussian Splatting is a technique that transforms collections of posed imagesImages for which we estimate the relative position and rotation of the camera in the scene. Usually, this is computed using Structure-from-Motion (SfM). into a volumetric representation called a radiance field. Generally, scenes can be created from collections of images captured from multiple overlapping viewpoints, either by taking multiple photographs from different angles or by sampling an input video while moving through the scene. For more complete details on 3D Gaussian Splatting, I encourage you to read the paper or watch this explanation video from Computerphile.
The scenes that are produced using 3D Gaussian Splatting are photorealistic and can be rendered at real-time rates using existing tools such as WebGL. However, I noticed that if the images used to train the 3D Gaussian Splat were swapped out with the line-drawing counterpartsWhile I transformed the images into line drawings, this transformation could be carried out using a number of other stylistic effects. then the resulting scene would depict a kind of 3D line drawing. Similar to regular sketchingIllustrating a 3D scene as a 2D drawing from a specific perspective., the lines that are rendered are view-dependant and change based on your perspective in the scene.
Swapping Source Images
 Figure 2. The transformed images can be used to create 3D line drawings by swapping them for the original images in one of two places, shown here in green. Either before using SfM to generate the sparse model and camera poses or prior to training the 3D Gaussian Splat. The former computes SfM points based on the transformed images, while the latter keeps the points from the original images and computes the rendering loss using the transformed images. Figure adapted from the original 3D Gaussian Splatting paper.
Figure 2. The transformed images can be used to create 3D line drawings by swapping them for the original images in one of two places, shown here in green. Either before using SfM to generate the sparse model and camera poses or prior to training the 3D Gaussian Splat. The former computes SfM points based on the transformed images, while the latter keeps the points from the original images and computes the rendering loss using the transformed images. Figure adapted from the original 3D Gaussian Splatting paper.Generating these 3D line drawings requires only a slight modification to the conventional process for generating 3D Gaussian Splats. At a high level, we simply swap the original images with the ones generated using Chan et al.'s method for transforming images into informative line drawings. This swap can happen in two places: prior to training the 3D Gaussian Splat or prior to estimating camera poses and sparse points using structure-from-motion (SfM).
When images are transformed prior to training the 3D Gaussian Splat, the camera poses and initial 3D Gaussians are derived from the original images but the loss is computed by comparing the rasterization output to the informative line drawing. As a result, the final scene also captures slight amounts of color that is not present in the transformed images. I believe this is a side-effect of intializing the 3D Gaussians using the original images. If you transform the images prior to applying SfM, the initialization and camera poses are based on the transformed images and the color artifacts are removed.
 Figure 3. (a) A 3D line drawing created by swapping the transformed images for the original ones prior to using SfM. (b) A 3D line drawing generated by swapping the transformed images for the original ones prior to training the 3D Gaussian Splat.
Figure 3. (a) A 3D line drawing created by swapping the transformed images for the original ones prior to using SfM. (b) A 3D line drawing generated by swapping the transformed images for the original ones prior to training the 3D Gaussian Splat.If you replace the images prior to applying SfM, there is less information to use when generating a sparse model and estimating camera poses. As a result, the process is more reliable when images are replaced prior to training the 3D Gaussian Splat. Additionally, if you're iterating on different styles and tweaking the transformation process, swapping prior to training the 3D Gaussian Splat lets you avoid re-running COLMAP (or other SfM tools) for each iteration. For the majority of my examples, I swapped the images prior to training the 3D Gaussian Splat. Figure 3 shows a comparison between scenes generated using these two methods.
Adding Color
 Figure 4. (a) A 3D line drawing created by swapping the original images with informative line drawings prior to training the 3D Gaussian Splat. Note that the slight amount of color is an artifact that is likely the result of initializing the 3D Gaussians from the original set of images. (b) A 3D line drawing that blends low-frequency color information from the original scene to produce a watercolor-like effect.
Figure 4. (a) A 3D line drawing created by swapping the original images with informative line drawings prior to training the 3D Gaussian Splat. Note that the slight amount of color is an artifact that is likely the result of initializing the 3D Gaussians from the original set of images. (b) A 3D line drawing that blends low-frequency color information from the original scene to produce a watercolor-like effect.I wanted to see how we could add some color information back into the generated line drawings and ultimately into the generated scenes. To do this, I generated a slightly modified hybrid image"A hybrid image is a picture that combines the low-spatial frequencies of one picture with the high spatial frequencies of another picture" - Oliva, Torralba & Schyns which blends color information from the original image into the line drawing to create a watercolor effect in the final image. Figure 4 shows the contour image and the blended hybrid image. There are a few scenes in the interactive example above that use this method of adding color, such as the Blended Caterpillar Scene, and Blended Lighthouse Scene.
A subtle, but interesting effect can be achieved by splicing together the source scene and color scene. By training a 3D Gaussian Splat to reconstruct photorealistic images from one set of perspectives and colored, contour images from another distinct set of perspectives, you can gradually transition styles within the same scene based on the viewing perspective. Figure 5 demonstrates this by orbiting around a scene in the Spliced Caterpillar Scene.
Combining Sketched and Real Scenes
 Figure 6. A collage image that segments out an object (in this example the tractor) in a scene and replaces it with the corresponding object from the stylized scene. This replacement, or collage, happens in image space prior to training the Gaussian Splat. (a) Inserts the contour style into the original scene. (b) Inserts the original scene into the stylized contour scene.
Figure 6. A collage image that segments out an object (in this example the tractor) in a scene and replaces it with the corresponding object from the stylized scene. This replacement, or collage, happens in image space prior to training the Gaussian Splat. (a) Inserts the contour style into the original scene. (b) Inserts the original scene into the stylized contour scene.Another experiment I tried was to create a collage scene that renders only the subject of the scene as a line drawing and leaves the background unaltered. To do this I used a Meta's Segment-Anything Model (SAM)To avoid manually specifying areas in the image to segment using SAM, I used LangSAM to automatically segment images based on a text prompt. to mask out the subject in each input photograph and replace it with the corresponding area from the generated line drawing image. The resulting scene is depicted in Figure 6 and can be explored here: Caterpillar Collage Scene.
Faster Generation & Lower Fidelity Sketches
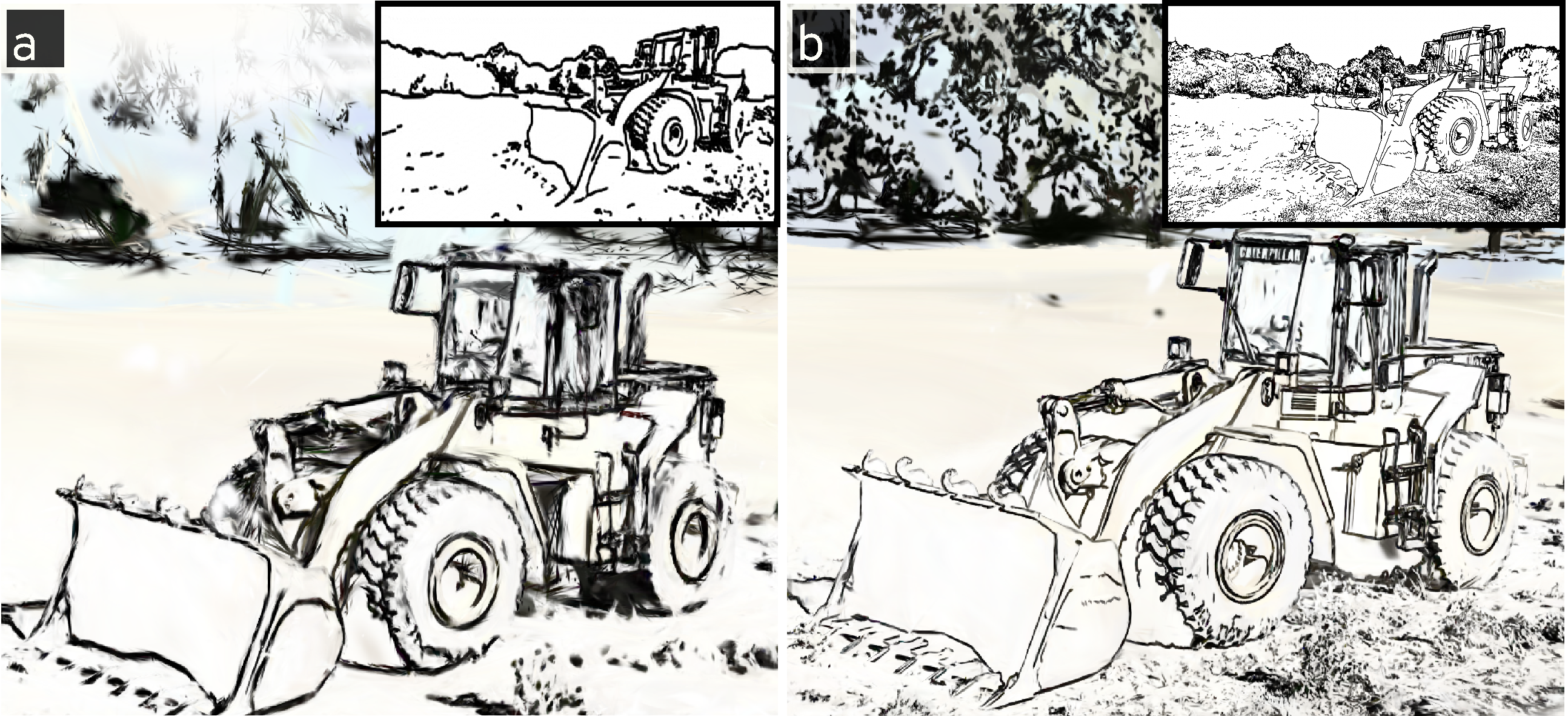 Figure 7. The same scene rendered by line drawings at two output resolutions. In each scene the inset image is one of the transformed images used to generate the scene. (a) 460x256 pixels. (b) 1940x1080 pixels.
Figure 7. The same scene rendered by line drawings at two output resolutions. In each scene the inset image is one of the transformed images used to generate the scene. (a) 460x256 pixels. (b) 1940x1080 pixels.The scenes so far have been trained on high resolution images (~1080p). This not only effects how long it takes to train the 3D Gaussian Splat, but also the fidelity of details captured in the line drawing. The lower resolution outputs capture the major lines that define the shape of the subject in the scene, while higher resolution outputs can pick up on more minor details in the scene. Figure 7 shows the same scene rendered at a variety of resolutions.
The following table describes the training time and number of splats generated for line drawings generated in a range of resolutions. Each scene is trained using the same parameters for 21,000 iterations. The final row describes the original scene using images from the Caterpillar scene in the Tanks and Temples Benchmark.
| Resolution | Training Time | Number of Splats | Uncompressed File Size (.ply) | Compressed File Size (.ksplat) |
|---|---|---|---|---|
| 232x128 | 3m 38s | 662,428 | 164 MB | 14.1 MB |
| 460x256 | 4m 31s | 1,105,383 | 274 MB | 24.5 MB |
| 920x512 | 6m 48s | 1,611,563 | 400 MB | 36.4 MB |
| 1940x1080 | 15m 27s | 2,046,676 | 507 MB | 46 MB |
| Original (1957x1090) | 15m 9s | 900,798 | 223 MB | 21 MB |
It is notable that a line drawing scene is roughly double the size of it's source scene in both number of splats and file size. I hypothesize that this is because splats are better suited at modelling large areas and textures than they are at strokes. As a result, a scene of a 3D line drawing must use more individual Gaussians to render long, thin lines in the scene.
Code
The original code to generate these is a mashup of scripts to orchestrate between the different libraries referenced in this post. In June 2026, I used Claude Code to turn my duct-taped mess into a more user-friendly workflow for creating these kinds of scenes: Splatline.
Contact
If you have thoughts about this work or would like to collaborate, I would love to hear from you. You can contact me at: tansh at amritkwatra dot com
Acknowledgements
Special thanks to Ritik Batra, Ilan Mandel & Thijs Roumen for their feedback and suggestions. This page was created using the open-source Tufte Project Pages template.